Debugging hard-to-reproduce Ruby memory leaks
Memory leaks are some of the more annoying issues we run into in software engineering. In general, with any kind of software bug, it's always preferable if you can reproduce the problem under controlled, "laboratory-like" circumstances. With certain kinds of problems, this is really hard or almost impossible. Memory leaks tend to lean towards that category. They are not always so easy to reproduce, and it's not always so easy to understand the reason why your (seemingly sane) code is causing a leak. At the same time, they are very rewarding to track down because of the warm feeling you get inside once you figure out root the cause!
(This post was greatly inspired by Oleg Dashevskii's excellent post "How I spent two weeks hunting a memory leak in Ruby", hereafter called "Two Weeks". Thank you for teaching us all a lot about memory leak debugging in general, and Ruby-related leaks in particular, Oleg!)
The post is much longer than it ought to be; I have been fairly extensive in detailing all the steps. If you're only interested in the final conclusions, feel free to scroll right to the end. ![]()
So, I have a memory leak in one of my applications, or that's what it seems like. The memory graph looks like this at the moment (the server is running on Amazon's EC2 cloud-based hosting):
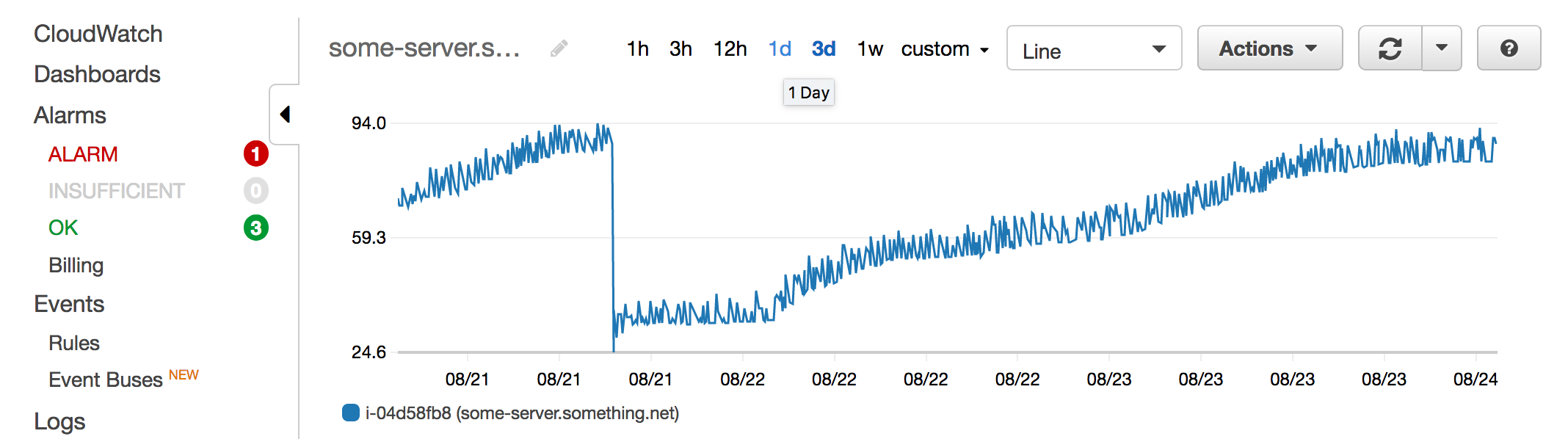
The point where the memory usage dropped greatly is when I restarted the application. After that, it's been gradually increasing, with occasional drops as the garbage collector has been running, reclaiming some (but not all) memory that has been allocated over time. A very clear sign that something is indeed leaking.
This application used to work well, with no need for systematic restarts or anything (unlike some other applications I know). What we did some months ago was move it from running on JRuby to MRI. That means that some Java-based Ruby extensions has now been replaced with C-based extensions, where there could theoretically be a new, unknown leak.
I looked into this a few weeks ago, and actually did manage to find a leak in the MongoDB Ruby driver via the use of the Ruby gem heapy, which btw is a great suggestion if you like me are getting started with Ruby heap analysis and memory leak debugging, but don't know where to start.
So, I set up a workaround for that in the affected application, but unfortunately this was not enough. As evidenced by the graph above, the leak prevails. What to do next?
Trying to figure out whether the leak is in Ruby code or a C extension
An important piece of information I learned when analyzing the Mongo leak mentioned earlier in this post was ObjectSpace tracing (via Sam Safrron's blog post) and heap dumping in Ruby. I added a .rb resource in my application that would start the tracing:
require 'objspace'
ObjectSpace.trace_object_allocations_start
Then I added another .rb resource which I could just make a GET request towards, to collect the tracing and dump it to a file:
file = File.open('/tmp/dump.json', 'w')
# Run the GC before dumping, to get better data.
GC.start
ObjectSpace.dump_all(output: file)
file.close()
I would then transfer this file to my local computer to be able to run the heapy analysis on it. Unfortunately, in this case, the heap dump looks fairly reasonable (this dump was generated yesterday):
$ heapy read dump.json
Analyzing Heap
==============
Generation: nil object count: 140135
Generation: 50 object count: 111
Generation: 51 object count: 493
Generation: 52 object count: 6
Generation: 53 object count: 262
Generation: 66 object count: 500
Generation: 67 object count: 6194
Generation: 68 object count: 16062
Generation: 69 object count: 48074
Generation: 70 object count: 257
Generation: 71 object count: 2229
Generation: 72 object count: 2
Generation: 73 object count: 3
Generation: 74 object count: 8
Generation: 77 object count: 196
Generation: 78 object count: 1
Generation: 88 object count: 23
Generation: 107 object count: 7
Generation: 158 object count: 3
Generation: 194 object count: 8
Generation: 216 object count: 17
Generation: 224 object count: 97
Generation: 225 object count: 8
Generation: 227 object count: 2040
Generation: 241 object count: 44
Generation: 242 object count: 8
Generation: 283 object count: 36
Generation: 401 object count: 7
Generation: 404 object count: 16
Generation: 405 object count: 77
Generation: 457 object count: 1
Generation: 470 object count: 36
Generation: 503 object count: 40
Generation: 511 object count: 21
Generation: 825 object count: 28
Generation: 1170 object count: 16
Generation: 1713 object count: 20
Generation: 1804 object count: 1
Generation: 2161 object count: 16
Generation: 2313 object count: 1
Generation: 2355 object count: 28
Generation: 2356 object count: 4
Generation: 2391 object count: 1
Generation: 2393 object count: 22
Generation: 2417 object count: 1
Generation: 2418 object count: 6
Generation: 2423 object count: 1
Generation: 2425 object count: 6
Generation: 2427 object count: 44
Generation: 2428 object count: 7
Generation: 2429 object count: 108
Generation: 2430 object count: 756
Generation: 2431 object count: 23
Sure, we have some objects retained over GC generations, but still, it doesn't look that bad. I mean, if we have sometimes 300 generations or more running (825-1170, 1170-1713, 1804-2161) without any object retained, it doesn't like we have a huge problem here. This indicates to me that the main source of the leak is probably not on the Ruby side. The dump is also fairly small (65 MiB), and I have a feeling that it ought to be greater in this case (where the process is already using something like 1500 MiB or so).
After restarting the process, to avoid running into problems in production, then continuing to let it grow a bit in size, I looked again. The memory usage for the process right now looks like this:
$ ps -fe | grep :8000 | grep -v grep
9999 31932 3108 0 07:16 ? 00:01:56 puma 3.9.1 (tcp://0.0.0.0:8000) [46]
$ ps -eo pid,rss | grep 31932
31932 793952
...so between 750 and 800 megabytes of memory.
Alright, but can we get some info on how large the actual Ruby heap is for this process? To see if it is memory that has been allocated from Ruby or elsewhere.
I read, but couldn't find any really clear explanation on how to determine the total heap size of a Ruby program. I learned that you can get a Hash like this by calling GC.stat:
{
"count": 1697,
"heap_allocated_pages": 1575,
"heap_sorted_length": 2243,
"heap_allocatable_pages": 0,
"heap_available_slots": 641972,
"heap_live_slots": 520807,
"heap_free_slots": 121165,
"heap_final_slots": 0,
"heap_marked_slots": 392645,
"heap_eden_pages": 1575,
"heap_tomb_pages": 0,
"total_allocated_pages": 2378,
"total_freed_pages": 803,
"total_allocated_objects": 136080650,
"total_freed_objects": 135559843,
"malloc_increase_bytes": 49880,
"malloc_increase_bytes_limit": 33554432,
"minor_gc_count": 1597,
"major_gc_count": 100,
"remembered_wb_unprotected_objects": 1505,
"remembered_wb_unprotected_objects_limit": 2564,
"old_objects": 389433,
"old_objects_limit": 444254,
"oldmalloc_increase_bytes": 61983056,
"oldmalloc_increase_bytes_limit": 91991565
}
Still, this didn't give me an immediate value of the total size of the heap. This StackOverflow post hinted that heap_sorted_length * 408 * 40 would give me the total heap, in bytes, so by dividing that with 1048576 I would get the total size in MiB.
That gives me, at the moment, the following:
2.4.1 :002 > (2243 * 408 * 40)/1048576
=> 34
Hmm. 34 megabytes. But we saw that the total resident size here is about 750 megabytes. It seems like the leak could perhaps be in an extension after all.
Now, it was time to try and reproduce the problem locally. To do this, I took a similar approach as in Two Weeks: to gather a collection of (idempotent, ideally) GET URLs from the production server logs. The logs weren't in the exact right format though, so I had to pipe them through a little awk script to get them into a usable shape.
Inconclusive logs because of Silverlight client
Here I ran into problems: I could easily get the request paths, being able to construct valid URLs, but the client in this case is an older Silverlight application that we haven't yet managed to replace with something else. And as some of you might know, HTTP requests generated by a Silverlight client are always sent as an HTTP POST request, with the X-Method header set to the real HTTP method (GET, DELETE, etc). This also has the consequence that the request parameters are not transmitted in the request URL, but are instead encoded in an HTTP POST body. Ergo: they are not logged in the server logs... This made it a lot harder to triage this, since many of the REST resources used by the application were using parameters.
I decided to keep things simple. How about using some "divide and conquer" strategy here. Let's divide the problem into two halves:
- It can be a problem in the core of our application server, or
- It can be a problem in one of the non-mandatory dependencies (or the application itself, but that seems unlikely if it's indeed a leak in non-Ruby code...)
There was a simple API endpoint in the app that was called Ping. It's whole GET handler was this method body:
{
response: 'Pong'
}
So: no external dependencies, no Trello, no MongoDB, no nothing. If this resource would indeed be leaking, it would mean that the problem is most likely in the core of the application server itself. I started the server and looked at the initial memory consumption (using the same strategy as above). The RSS was about 55 MiB.
I then initiated the siege call:
$ siege -v -c 15 http://localhost:8000/api/Ping
...and let it run for 10 minutes. It increased a bit, but not significantly enough. In other words, it didn't seem to give me any clues as to what was leaking.
OK, let's try with some other parts of the application instead. I went back to the list of URLs I had and excluded the Ping endpoint from it. I tried to find resources with a low number of external dependencies (the app uses MongoDB and Trello, and the Trello API is rate-limited). I can start mocking the Trello calls with VCR and/or webmock, but since I lost all the parameters it's easier for me to start with just hitting one or a few URLs (since I'll have to recreate the URL parameters manually).
I took out a list of the most commonly used URLs:
# cat /var/log/syslog | grep " GET " | awk '{ print $14 }' | grep -v Ping | sort | uniq -c | sort -n --reverse
855 /api/WeeklyFlex
477 /api/Flex
424 /api/UserTrelloBoards
424 /api/TrelloBoards
377 /api/OpenTimesheets
17 /api/TrelloCardsInDevelopment
11 /api/Timesheet
4 /api/TrelloBoard
2 /api/Users
2 /api/User
2 /api/Efforts
The WeeklyFlex and Flex resources seemed like good candidates to start with. They were also good in the sense that they did not have any Trello dependency, only MongoDB. So let's continue our investigation by siegeing these REST resources a bit:
$ siege -v -c 3 -f urls.txt
(15 simultaneous clients hammering the server turned out to be too much for the connection pooling settings in use here.)
I once again started looking at the RSS for the process, and it seemed actually to have been started to leak now. Memory usage was first 168428 KiB, then after a while 200672, then later again 201036. But there it seemed to stop. Hmm??? 🤔
I looked at the heap_live_slots. 699981 first. 969132 later. This is interesting: could it actually be that we have a memory leak on the Ruby side of the world after all? If we didn't, we should not see increasing values here. The heap slots being used by Ruby should stay more or less constant over time.
I decided it was time to draw a nice graph to get an overview of this, once again inspired by Dashevskii. The figures weren't that easy to interpret right now, so a picture would hopefully make things a bit clearer.
I added the gc_tracer gem, just like in Two Weeks, to get more data for the benchmark. Then I started the tracing.
I looked at the processing times for HTTP requests, and they were honestly quite depressing. It felt like things got worse over time, even more than would be expected. But even upon startup, the times for these "should-be" quite simple Ruby resources weren't that impressing. I mean, seriously. Gathering some data from a MongoDB database and producing a result, "how hard can that be"? Of course, if the Mongo database lacks the proper indexes (which can very well be the case here), it will be slower than it ought to be. If the code is less efficient because it uses a poor algorithm, that doesn't make things better, and I think this can well be the case here.
The problem with the HTTP requests being slow here was that the siege execution didn't really make very many HTTP requests, since each request took literally seconds to respond to. Less than optimal if you want to stress-test your code under laboratory-like circumstances, but anyway, it was worth letting it run for a while so I left the machine on overnight.
Plotting the data to an image
I used the following gnuplot script; I couldn't make Oleg's script work right OOTB so had I to tweak the column it was taking its data from, set up a y2range etc. Here is the script (I took out a subset of the data to get it to look reasonable):
# Heavily based on the gnuplot script provided by Oleg Dashevskii here:
# http://www.be9.io/2015/09/21/memory-leak/
set xdata time
set timefmt '%s'
set format x '%H:%M'
set y2tics in
set y2label 'Kilobytes'
set ylabel 'Objects'
set y2range [0:1000000000]
set term png
set output "graph.png"
plot 'log/gc_converted.log' \
using 2:25 \
with lines \
lc rgb 'red' \
title columnhead, \
'' \
\
using 2:35 \
with lines \
lc rgb 'blue' \
title columnhead \
axes x1y2
This would give me a graph that looked like this:
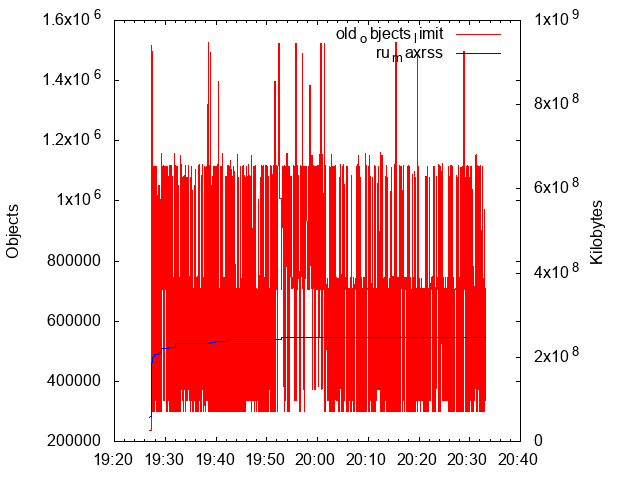
The red figure is the number of Ruby objects allocated. It looks pretty much like in Dashevskii's image.
{kind=link}
The blue line is the RSS (Resident Set Size). The picture doesn't show it so clearly, but it was during the included hour and a half growing from 54 MiB to 236 MiB. As mentioned, I had left the machine on during the night, and during this time it grew to 264 MiB. It felt like the growing was "evening out". Too bad the HTTP resources in question were so incredibly slow; I think I would have gotten a better result if I would have been able to run more iterations during this time. (It was only 52168 hits during these hours, or around 1.44 transactions/second - very slow by any reasonable means.)
Investigating a false track: trivial Mongo querying
I wasn't quite pleased with the outcome of the stress testing yet, so I decided to make a simple .rb file that would do a trivial Mongo query, and then return, to be able to see if I could be able to handle many more requests per second, and hence perhaps also trigger the potential memory leak faster. Something like this (mongo is a method which grabs a connection from the MongoDB connection pool and yields it to the block passed to it):
mongo do |db|
# The collection contains about 450 records. The result will be read, and then JSON serialized on every request.
db['holidays'].find.to_a
end
Trivial indeed. With this kind of script, the execution for a single invocation would go down to just a few milliseconds, meaning I could hammer the server with many more requests per hour, hopefully provoking the leak.
I let it run overnight, but unfortunately, I was quite displeased with the result. The RSS only went up from 55 megabytes early on to 74 megabytes after this session:
Lifting the server siege...
Transactions: 596895 hits
Availability: 100.00 %
Elapsed time: 32111.03 secs
Data transferred: 1524.43 MB
Response time: 0.01 secs
Transaction rate: 18.59 trans/sec
Throughput: 0.05 MB/sec
Concurrency: 0.24
Successful transactions: 596895
Failed transactions: 0
Longest transaction: 0.69
Shortest transaction: 0.00
20 megabytes more being used after 600 000 requests. That's not a leak to me, it can be just as much "regular memory usage", more structures being allocated as the program was running etc. Perhaps the Ruby interpreter is also JITting some of the code, as one of my colleagues was suggesting the other day when we were discussing the leak. I don't know, I haven't studied the MRI internals to that extent. But anyway, to me, this is not evidence for a leak.
Another false track: Webmock leaking
I had to get back to the drawing board. Maybe it was now time to run the full set of requests, even though it would be a bit more work to set up with the VCR stubbing etc...
Said and done: I recreated a more complete list of URLs. It wasn't so many minutes of work after all. I set up VCR mocking, ran the requests once (to populate the VCR cassette), and then disabled all "live" HTTP requests to Trello (just to be 100% sure that no requests would start to be made). The record: :none flag is useful in this case.
Here are the results, after running 90 000 requests towards the server:
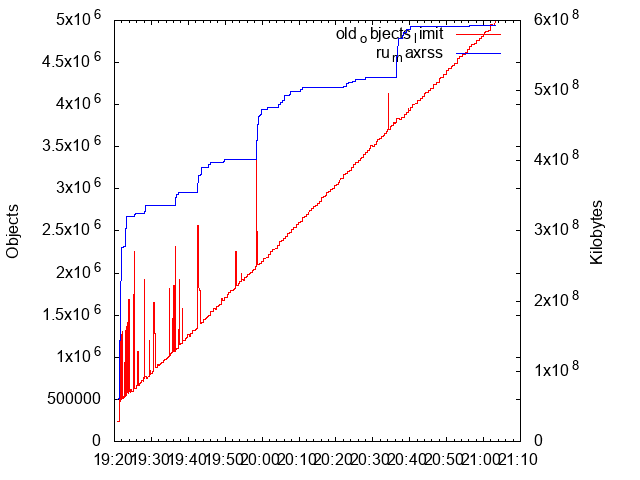
This was interesting indeed, and a bit unexpected! The statistics clearly show that something is leaking here, but it seems to be very much on the Ruby side (since the red graph indicates that the number of Ruby objects are expanding). I strongly suspected VCR/Webmock would be the cause. Unfortunately, I hadn't enabled ObjectSpace tracing here, so I had to restart the process, enable tracing via the approach mentioned earlier in this blog post, and then re-start the siege once more...
I looked at the heapy dump, which seemed to unfortunately support the claim that Webmock was the source of the leak here (it was present in the list of High Ref Counts and object count, with high numbers, indicating that data wasn't able to be completely freed after requests). I would now have to choose between either a few different paths:
- Skip
webmockand run towards the real Trello APIs. Not too cool, I wanted to avoid this path. - Skip the specific HTTP REST resources which had a Trello dependency. This would make the test cases pretty much the same as I'd already tested (doing Mongo queries, albeit more sophisticated in this case), and verified to not be leaking.
- Go straight to the
jemallocdebugging. It's quite likely that this is the route that I would end up having to take anyway, but since it was late at night, I chose #2 for now to let it run overnight, just to see if it would provoke the leak.
It's quite likely that this is the route that I would end up having to take anyway, but since it was late at night, I chose #2 for now to let it run overnight, just to see if it would provoke the leak.
This time it looked like this:
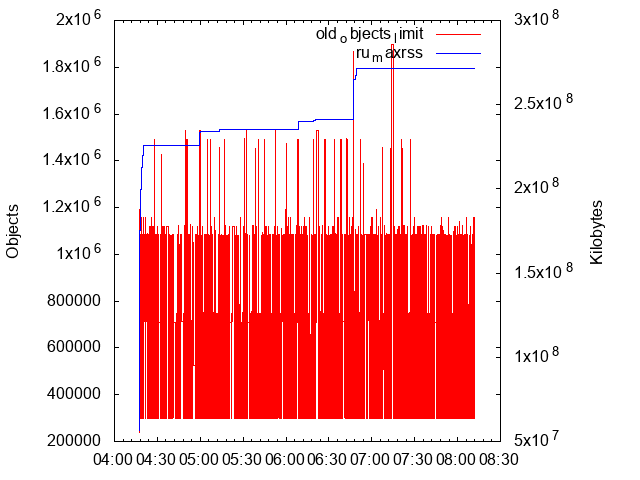
Maybe leaking somewhat (RSS size up to 129 megs, after 190 000 transactions), but at least not leaking on the Ruby side of the world.
The weekend was over and during it, I had to restart the production service once more, because the machine was down on its knees. I looked at the production server the day after to see how it's RSS and old_objects_limit was looking:
- RSS: around 800 MiB
old_objects: 380124
A bit high, but comparing with the graph, it looked it was still well within the "red area". No clear sign of any leak in Ruby code there.
Giving jemalloc a try
Now it was time to try the jemalloc track, again inspired by Two Weeks. I first compiled jemalloc from source:
$ autoconf
$ ./configure --enable-debug --enable-prof
$ make && sudo make install
(make install gave errors about doc file, which seems to be non-critical so I'm ignoring them for now.)
Then I compiled my own Ruby 2.4.1 with jemalloc enabled:
$ ./configure --with-jemalloc --with-openssl-dir=/usr/local/opt/openssl --prefix=$HOME/ruby-2.4.1-dbg --disable-install-doc
$ make -j8 # to make it build a bit faster.
$ make install
Then I made this my default Ruby (rvm use system and prepended it to the PATH), and tried setting the MALLOC_CONF environment variable to get some more info on waht's going on. I ran some Ruby code. Absolutely nothing was printed.
After fiddling around for a while, it turned out that on OS X, the env variable is named JE_MALLOC_CONF by default. I also found that there was actually some built-in leak detection in jemalloc which seemed really promising. So I set it up like this:
$ export JE_MALLOC_CONF='prof_leak:true,narenas:1,stats_print:true,prof:true'
This would at least give me something when I shut down my program, which looked as a good start.
I first started our application server, without performing any requests. This is the output on shutdown:
___ Begin jemalloc statistics ___
Version: 5.0.1-25-gea91dfa58e11373748f747041c3041f72c9a7658
Assertions enabled
config.malloc_conf: ""
Run-time option settings:
opt.abort: true
opt.abort_conf: true
opt.metadata_thp: false
opt.retain: false
opt.dss: "secondary"
opt.narenas: 1
opt.percpu_arena: "disabled"
opt.dirty_decay_ms: 10000 (arenas.dirty_decay_ms: 10000)
opt.muzzy_decay_ms: 10000 (arenas.muzzy_decay_ms: 10000)
opt.junk: "true"
opt.zero: false
opt.tcache: true
opt.lg_tcache_max: 15
opt.prof: true
opt.prof_prefix: "jeprof"
opt.prof_active: true (prof.active: true)
opt.prof_thread_active_init: true (prof.thread_active_init: true)
opt.lg_prof_sample: 19 (prof.lg_sample: 19)
opt.prof_accum: false
opt.lg_prof_interval: -1
opt.prof_gdump: false
opt.prof_final: false
opt.prof_leak: true
opt.stats_print: true
opt.stats_print_opts: ""
Arenas: 1
Quantum size: 16
Page size: 4096
Maximum thread-cached size class: 32768
Allocated: 52968016, active: 57049088, metadata: 3003896, resident: 70508544, mapped: 73912320, retained: 0
n_lock_ops n_waiting n_spin_acq n_owner_switch total_wait_ns max_wait_ns max_n_thds
background_thread: 0 0 0 0 0 0 0
ctl: 3 0 0 1 0 0 0
prof: 1134 0 0 18 0 0 0
arenas[0]:
assigned threads: 1
uptime: 5213946738
dss allocation precedence: disabled
decaying: time npages sweeps madvises purged
dirty: 10000 2549 1 6 32
muzzy: 10000 32 0 0 0
allocated nmalloc ndalloc nrequests
small: 30341712 361691 94182 991059
large: 22626304 734 357 734
total: 52968016 362425 94539 991793
active: 57049088
mapped: 73912320
retained: 0
base: 2883184
internal: 120712
tcache: 290536
resident: 70508544
n_lock_ops n_waiting n_spin_acq n_owner_switch total_wait_ns max_wait_ns max_n_thds
large: 75 0 0 4 0 0 0
extent_avail: 3956 0 0 54 0 0 0
extents_dirty: 7364 0 5 85 0 0 0
extents_muzzy: 2988 0 0 43 0 0 0
extents_retained: 2982 0 0 43 0 0 0
decay_dirty: 105 0 0 3 0 0 0
decay_muzzy: 103 0 0 3 0 0 0
base: 3960 0 0 54 0 0 0
tcache_list: 29 1 0 24 45621 45621 1
bins: size ind allocated nmalloc ndalloc nrequests curregs curslabs regs pgs util nfills nflushes newslabs reslabs n_lock_ops n_waiting n_spin_acq total_wait_ns max_wait_ns
8 0 197024 29838 5210 49729 24628 53 512 1 0.907 350 75 57 43 527 0 0 0 0
16 1 302448 22719 3816 40224 18903 82 256 1 0.900 345 71 87 48 524 0 0 0 0
32 2 1393280 55072 11532 158805 43540 364 128 1 0.934 845 132 421 138 1471 0 0 0 0
48 3 2362512 67425 18206 162162 49219 219 256 3 0.877 733 198 233 537 1194 0 0 0 0
64 4 1423168 35288 13051 149591 22237 375 64 1 0.926 934 234 418 1143 1645 0 0 0 0
80 5 1417040 26970 9257 81486 17713 79 256 5 0.875 637 131 85 304 875 1 0 23449 23449
96 6 1944960 23998 3738 48500 20260 168 128 3 0.942 327 75 175 169 600 0 1 0 0
112 7 852320 10658 3048 18819 7610 32 256 7 0.928 431 85 36 83 572 0 0 0 0
128 8 755968 10443 4537 32145 5906 200 32 1 0.922 486 162 235 568 1668 0 0 0 0
160 9 2330080 16569 2006 56468 14563 118 128 5 0.964 477 66 122 109 685 0 0 0 0
192 10 683904 5147 1585 11327 3562 65 64 3 0.856 177 88 77 69 372 0 0 0 0
224 11 4904032 23202 1309 33471 21893 174 128 7 0.982 273 42 181 51 521 0 0 0 0
256 12 544768 2723 595 4900 2128 143 16 1 0.930 216 73 156 72 476 0 0 0 0
320 13 1141120 5447 1881 9021 3566 62 64 5 0.898 179 89 85 64 405 0 0 0 0
384 14 809088 2916 809 5660 2107 70 32 3 0.940 167 82 85 84 419 0 0 0 0
448 15 1299200 4182 1282 4345 2900 48 64 7 0.944 150 87 62 55 381 0 0 0 0
512 16 477184 1287 355 2059 932 125 8 1 0.932 192 79 141 76 522 0 0 0 0
640 17 1015680 8895 7308 100467 1587 57 32 5 0.870 363 267 112 1028 973 0 0 0 0
768 18 934656 1663 446 2353 1217 80 16 3 0.950 135 72 96 61 540 0 0 0 0
896 19 663936 1439 698 1792 741 25 32 7 0.926 155 94 41 66 456 0 0 0 0
1024 20 486400 1705 1230 7090 475 145 4 1 0.818 370 174 241 510 919 0 0 0 0
1280 21 737280 1154 578 3703 576 42 16 5 0.857 163 95 60 54 376 0 0 0 0
1536 22 493056 534 213 913 321 44 8 3 0.911 106 83 67 48 295 0 0 0 0
1792 23 338688 381 192 587 189 13 16 7 0.908 71 78 23 26 198 0 0 0 0
2048 24 339968 348 182 418 166 86 2 1 0.965 83 79 162 41 434 0 0 0 0
2560 25 343040 275 141 548 134 19 8 5 0.881 67 73 34 28 205 0 0 0 0
3072 26 436224 311 169 428 142 42 4 3 0.845 75 80 68 44 265 0 0 0 0
3584 27 182784 139 88 207 51 7 8 7 0.910 52 58 18 8 155 0 0 0 0
4096 28 315392 222 145 326 77 77 1 1 1 60 58 222 0 501 0 0 0 0
5120 29 250880 170 121 386 49 14 4 5 0.875 48 58 42 26 192 0 0 0 0
6144 30 184320 184 154 350 30 19 2 3 0.789 41 53 80 37 303 0 1 0 0
7168 31 35840 53 48 231 5 2 4 7 0.625 20 36 15 4 100 0 0 0 0
8192 32 483328 178 119 1653 59 59 1 2 1 46 56 178 0 415 0 1 0 0
10240 33 143360 86 72 511 14 8 2 5 0.875 31 42 40 10 161 0 1 0 0
12288 34 61440 42 37 211 5 5 1 3 1 20 33 42 0 148 0 0 0 0
14336 35 57344 28 24 173 4 3 2 7 0.666 8 21 13 4 68 0 0 0 0
large: size ind allocated nmalloc ndalloc nrequests curlextents
16384 36 5259264 609 288 974 321
20480 37 20480 5 4 5 1
24576 38 122880 10 5 15 5
28672 39 28672 13 12 13 1
32768 40 524288 20 4 22 16
40960 41 40960 3 2 3 1
49152 42 49152 6 5 6 1
57344 43 0 1 1 1 0
65536 44 0 4 4 4 0
81920 45 163840 2 0 2 2
98304 46 98304 6 5 6 1
---
131072 48 1703936 27 14 27 13
---
196608 50 196608 5 4 5 1
---
393216 54 0 4 4 4 0
---
524288 56 524288 2 1 2 1
---
786432 58 786432 3 2 3 1
---
1048576 60 11534336 12 1 12 11
---
1572864 62 1572864 2 1 2 1
---
--- End jemalloc statistics ---
retained: 0 looks good; I understand that to mean that no memory leak occurred for this simple test case.
I then ran a single HTTP request. Only one, to make it simple for now, then shut down the application server again to see what it would print.
Weird, no immediate sign of leaking actually! I then decided to let siege hammer the server for a while (it was bedtime anyway...) to see what I'd get out of that. I also enabled lg_prof_sample:0,prof_final:true, as mentioned on the jemalloc wiki. This made the process much slower to start, probably because the profiler incurred a significant performance penalty.
I left the machine on and then went to do some dishes. When I got back, the process was using a total of 13 GiB of virtual memory, with an RSS of around 6 GiB. Impressive! I looked at the stats again, which showed that there was a large number (3 863 073 allocations) of 128 byte blocks, and also a large number (15 550 835) of 16 KiB blocks. Since I had enabled prof_final:true, I had a .heap file that I could try and investigate now to see if it would give me some details... jemalloc includes a little tool called jeprof, which was mentioned on the wiki page previously mentioned. I tried it out to see if it could give me some indication as to where the main source of allocations was coming from. I suspected the Ruby built-in allocator, since it allocated memory in "pages" and I had a feeling that these pages were 16 KiB each.
$ jeprof --show_bytes `which ruby` jeprof.28824.0.f.heap
Using local file /Users/plundberg/ruby-2.4.1-dbg/bin/ruby.
Using local file jeprof.28824.0.f.heap.
Welcome to jeprof! For help, type 'help'.
(jeprof) top
Total: 92707579 B
92707579 100.0% 100.0% 92707579 100.0% 0x0000000103799a8c
0 0.0% 100.0% 98304 0.1% 0x000000010346c68f
0 0.0% 100.0% 482184 0.5% 0x000000010346c6aa
0 0.0% 100.0% 1299385 1.4% 0x000000010346c6b6
0 0.0% 100.0% 30965952 33.4% 0x000000010346c6be
0 0.0% 100.0% 44712 0.0% 0x000000010346c6f4
0 0.0% 100.0% 83760 0.1% 0x000000010346c7be
0 0.0% 100.0% 320 0.0% 0x000000010346c7d5
0 0.0% 100.0% 769968 0.8% 0x000000010346c7fa
0 0.0% 100.0% 80 0.0% 0x000000010346caa4
Interesting! One method doing all the allocations. Just like in Two Weeks, for whatever reason it didn't resolve the function addresses. I tried to fire up gdb, just to realize it wasn't installed on macOS by default... but lldb was.
I tried to use the image lookup --address 0x0000000103799a8c and image lookup -a 0x0000000103799a8c commands, to no avail; they didn't find any matching function. Annoying indeed. I felt that my lack of knowledge around macOS intricacies in this area was limiting me; I know much more about debugging on Linux/GNU systems, since that's what I've been doing quite a lot in the chaos project. So, either I could spend a bit of time here, learning new things (which is obviously a good thing...) or I can go with the "simpler" approach of instead trying to utilize the knowledge I already had.
Moving over to debugging in a Linux VM
Said and done, I decided to set up a Ubuntu-based Vagrant image for this. I already had a Vagrantfile for another app with similar characteristics, so it wasn't that much work to get it set up. Running it all in Ubuntu would make sense anyway, since the deployment environment is Ubuntu and it might be that the problem only manifests on Linux (well, I don't think so since we saw similar tendencies on macOS but still, it makes sense to try and reproduce a problem in the same kind of environment).
Of course, this meant I had to recompile jemalloc and ruby once more, but since I saved the commands here it wasn't that much work. ![]() (apart from making sure
(apart from making sure gcc, g++, libssl-dev, libpg-dev and make was installed...)
Then I had problems with jemalloc, refusing some of the options I passed to it:
<jemalloc>: Invalid conf pair: prof_leak:true
<jemalloc>: Invalid conf pair: prof:true
<jemalloc>: Invalid conf pair: lg_prof_sample:0
<jemalloc>: Invalid conf pair: prof_final:true
Recompiling jemalloc and Ruby didn't really help. I decided to wipe my ruby-2.4.1 folder and unpack the dist .tar.gz file again (I had mounted my macOS volume into the Vagrant VM, to make things simpler, but in reality it didn't...)
It turned out that the make install I did in the Ruby folder had cached the "bad" version of jemalloc (compiled without profiling enabled) in its lib/ folder... Once I removed those files, re-ran make install in jemalloc and ruby-2.4.1, profiling was back up and working. And even better; just running ruby -v would indicate a leak! (running with MALLOC_CONF set to prof_leak:true,narenas:1,stats_print:true,prof:true,lg_prof_sample:0,prof_final:true)
<jemalloc>: Leak approximation summary: ~889696 bytes, ~6033 objects, >= 5947 contexts
<jemalloc>: Run jeprof on "jeprof.31594.0.f.heap" for leak detail
Maybe this was a Linux-only issue after all? I was excited and couldn't wait to investigate the leak more in detail.
ubuntu@time:/vagrant$ jeprof `which ruby` jeprof.31594.0.f.heap
Using local file /home/ubuntu/ruby-2.4.1-dbg/bin/ruby.
Using local file jeprof.31594.0.f.heap.
Welcome to jeprof! For help, type 'help'.
(jeprof) top
Total: 0.8 MB
0.2 28.9% 28.9% 0.2 28.9% objspace_xmalloc0
0.2 24.7% 53.5% 0.2 24.7% objspace_xcalloc
0.2 22.1% 75.6% 0.2 22.1% aligned_malloc (inline)
0.1 9.2% 84.9% 0.1 9.2% Init_Method
0.1 9.2% 94.1% 0.1 9.2% std::__once_callable
0.0 3.0% 97.1% 0.0 3.0% objspace_xrealloc.isra.72
0.0 1.8% 98.9% 0.0 1.8% stack_chunk_alloc (inline)
0.0 0.4% 99.4% 0.2 22.5% heap_page_allocate (inline)
0.0 0.4% 99.8% 0.0 0.4% _nl_intern_locale_data
0.0 0.1% 99.9% 0.0 0.1% __GI__IO_file_doallocate
(jeprof)
Very interesting! objspace_xmalloc0, similar to Two Weeks but not exactly the same (it seemed to be a method that has been introduced since Ruby 2.2.3, when I looked briefly at the Ruby source code.)
Trouble with pthread_create because of a bad jemalloc version
So, this was seemingly the Ruby interpreter leaking memory when running ruby -v. However, it did also give a warning about pthread_create failing:
<main>: warning: pthread_create failed for timer: Invalid argument, scheduling broken
Could this be the cause and this again being a "false track", leading me nowhere...? I disabled the MALLOC_CONF but still got a warning from Ruby about pthread_create. I googled and found this SO thread but I was running this on a 64-bit VM so it shouldn't be the issue. I googled a bit more but couldn't find any obvious cause; I even ran the Ruby via ltrace to trace the library calls (but was mostly just saddened about the extreme number of memory allocations being made for a simple call to ruby -v ![]() )
)
I decided to recompile Ruby once more, from a clean source (since I had changed the jemalloc being used without doing a full recompile, or that's how I remembered it). I also wanted to install the full list of build dependencies for the Ubuntu package first, just to see if it would help to get rid of the warning:
ubuntu@time:/vagrant$ sudo apt-get install autotools-dev bison chrpath coreutils debhelper dh-autoreconf file libffi-dev libgdbm-dev libgmp-dev libncurses5-dev libncursesw5-dev libreadline6-dev libssl-dev libyaml-dev netbase openssl procps systemtap-sdt-dev tcl8.6-dev tk8.6-dev zlib1g-dev
It didn't help, the error persisted. I tried upgrading the Ubuntu version, to the latest Vagrant box (from 20170303.1.0 to 20170822.0.0), didn't help either.
This was the point when I started asking in the #ruby channel on IRC. I was out of ideas. I got some suggestions there, and I recompiled Ruby without jemalloc - which made the error go away! I recompiled with jemalloc again, and the error was back. So, something was obviously not working as it should with my jemalloc. I reported this to the jemalloc maintainers - changing to jemalloc 5.0.1 resulted in a binary that did not emit these phtread-related errors.
Finding the methods performing the majority of the allocations
The pthread_create issue was indeed gone, but the leak still remained. Running ruby -v with the previously mentioned MALLOC_CONF rules indicated that memory allocated by objspace_xmalloc0 was indeed not being returned as it should. I looked at the Ruby issue tracker and found bug #12954, which hinted that this might actually be "by design" and not related to my particular memory leak at all... So, leaving it for now; it feels odd but it's a tradeoff that the Ruby developers have taken. (I personally think it would have made more sense to use sbrk or mmap instead of malloc/free if you indeed do not intend to release all the memory you have been allocating, not even at shutdown... but I don't know; I haven't studied the background to this decision. It would have made this kind of debugging a lot harder, so in that sense I'm happy that they didn't do it like that. ![]() )
)
Anyway, time to run my own application again, and put it under siege. I was kind of tired of the whole debugging, hoping it would end soon... This was now Tuesday night, and I started deep-digging into this on Thursday the week before.
I first started the application server without performing any requests, just to see what jemalloc would report. It took a long time just to start it, since I enabled a lot of the profiling flags in MALLOC_CONF again. It would actually get killed before it even got started!
ubuntu@time:/vagrant$ MALLOC_CONF='prof_leak:true,narenas:1,stats_print:true,prof:true,lg_prof_sample:0,prof_final:true' bundle exec uxfactory
Killed
I strongly suspect that the fact that the VirtualBox VM was only allocated 1 GiB was the problem here. I tried to use less aggressive profiling flags instead:
ubuntu@time:/vagrant$ MALLOC_CONF='prof_leak:true,prof_final:true,narenas:1,stats_print:true' bundle exec uxfactory
jemalloc indicated a leak this time also, and looking at the top stats was interesting. What are those aligned_malloc calls, for example?
ubuntu@time:/vagrant$ jeprof `which ruby` jeprof.30872.0.f.heap
Using local file /home/ubuntu/ruby-2.4.1-dbg/bin/ruby.
Using local file jeprof.30872.0.f.heap.
Welcome to jeprof! For help, type 'help'.
(jeprof) top
Total: 116.6 MB
77.3 66.2% 66.2% 77.3 66.2% objspace_xmalloc0
21.8 18.7% 85.0% 21.8 18.7% aligned_malloc (inline)
13.5 11.6% 96.6% 13.5 11.6% objspace_xcalloc
2.5 2.1% 98.7% 2.5 2.1% objspace_xrealloc.isra.72
1.0 0.9% 99.6% 22.8 19.6% heap_page_allocate (inline)
0.5 0.4% 100.0% 0.5 0.4% add_bitset (inline)
0.0 0.0% 100.0% 0.5 0.4% Init_nokogiri
0.0 0.0% 100.0% 0.5 0.4% Init_openssl
0.0 0.0% 100.0% 0.5 0.4% Init_ossl_engine
0.0 0.0% 100.0% 73.4 62.9% __clone
jeprof has a nice option to generate a PDF or a GIF image, which shows the call graphs for these allocations. Here is what it looks like (use "View image" in your browser if the image is too small to be readable, it can sometimes let you zoom in a bit):
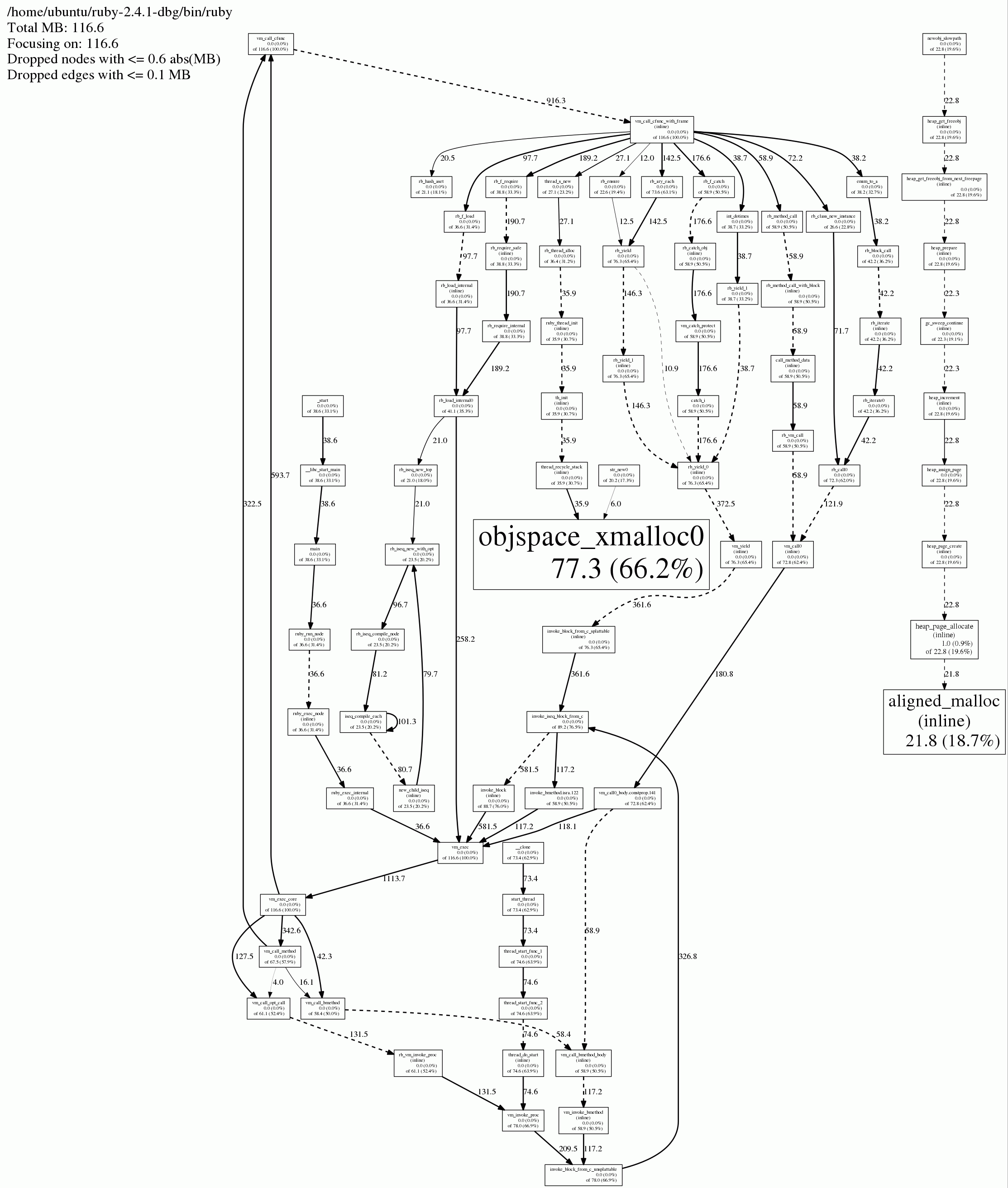
Apparently, the calls to aligned_malloc all had their roots in newobj_slowpath. So, the conclusion is that the top 4-5 methods here doing the allocations all come from the Ruby VM. I still had the feeling I was looking for a needle in a haystack... It had to be there, somewhere.
I re-ran the server with 1000 requests again, since I forgot to take out the stats_print output. Here it is:
<jemalloc>: Leak approximation summary: ~83084117 bytes, ~309 objects, >= 100 contexts
<jemalloc>: Run jeprof on "jeprof.6492.0.f.heap" for leak detail
___ Begin jemalloc statistics ___
Version: 5.0.1-0-g896ed3a8b3f41998d4fb4d625d30ac63ef2d51fb
Assertions enabled
config.malloc_conf: ""
Run-time option settings:
opt.abort: true
opt.abort_conf: true
opt.retain: true
opt.dss: "secondary"
opt.narenas: 1
opt.percpu_arena: "disabled"
opt.background_thread: false (background_thread: false)
opt.dirty_decay_ms: 10000 (arenas.dirty_decay_ms: 10000)
opt.muzzy_decay_ms: 10000 (arenas.muzzy_decay_ms: 10000)
opt.junk: "true"
opt.zero: false
opt.tcache: true
opt.lg_tcache_max: 15
opt.prof: true
opt.prof_prefix: "jeprof"
opt.prof_active: true (prof.active: true)
opt.prof_thread_active_init: true (prof.thread_active_init: true)
opt.lg_prof_sample: 19 (prof.lg_sample: 19)
opt.prof_accum: false
opt.lg_prof_interval: -1
opt.prof_gdump: false
opt.prof_final: true
opt.prof_leak: true
opt.stats_print: true
opt.stats_print_opts: ""
Arenas: 1
Quantum size: 16
Page size: 4096
Maximum thread-cached size class: 32768
Allocated: 92656168, active: 112623616, metadata: 9309512, resident: 188674048, mapped: 192122880, retained: 2291953664
n_lock_ops n_waiting n_spin_acq n_owner_switch total_wait_ns max_wait_ns max_n_thds
background_thread: 4 0 0 1 0 0 0
ctl: 2 0 0 1 0 0 0
prof: 213249 0 0 36993 0 0 0
arenas[0]:
assigned threads: 1
uptime: 27711768648555
dss allocation precedence: secondary
decaying: time npages sweeps madvises purged
dirty: 10000 16337 3265 267474 2941747
muzzy: 10000 0 0 0 0
allocated nmalloc ndalloc nrequests
small: 31519272 82487981 82209113 135693660
large: 61136896 354585 353342 354585
total: 92656168 82842566 82562455 136048245
active: 112623616
mapped: 192122880
retained: 2291953664
base: 9126400
internal: 183112
tcache: 341920
resident: 188674048
n_lock_ops n_waiting n_spin_acq n_owner_switch total_wait_ns max_wait_ns max_n_thds
large: 32651 0 0 3092 0 0 0
extent_avail: 1163820 2 2 49767 0 0 1
extents_dirty: 3142989 13 50 99960 0 0 1
extents_muzzy: 12691 0 0 6569 0 0 0
extents_retained: 550188 0 0 8298 0 0 0
decay_dirty: 90112 0 0 6196 0 0 0
decay_muzzy: 85811 0 0 6196 0 0 0
base: 19633 0 1 1356 0 0 0
tcache_list: 178 3 1 123 20000000 8000000 2
bins: size ind allocated nmalloc ndalloc nrequests curregs curslabs regs pgs util nfills nflushes newslabs reslabs n_lock_ops n_waiting n_spin_acq total_wait_ns max_wait_ns
8 0 195736 42101 17634 51640 24467 50 512 1 0.955 4539 3456 52 3517 8314 0 0 0 0
16 1 300912 55543 36736 204114 18807 78 256 1 0.941 16722 6416 81 5537 23312 2 0 8000000 8000000
32 2 1434816 19014057 18969219 23278862 44838 427 128 1 0.820 1195772 194841 86465 160738 1563218 2 1 0 0
48 3 2482704 6643606 6591883 8303478 51723 319 256 3 0.633 295211 71322 6847 71802 379998 0 0 0 0
64 4 1663424 27541809 27515818 50577959 25991 1029 64 1 0.394 1927193 435330 308738 313492 2979060 0 1 0 0
80 5 1452320 3842845 3824691 5375456 18154 105 256 5 0.675 280513 43820 3398 46423 331114 0 2 0 0
96 6 2147232 12436097 12413730 26804404 22367 313 128 3 0.558 730118 129348 52820 122703 964883 1 0 0 0
112 7 784560 722481 715476 795391 7005 38 256 7 0.720 48417 17587 235 16989 66526 0 0 0 0
128 8 737536 835301 829539 1308530 5762 246 32 1 0.731 103744 32016 5750 66445 302932 0 0 0 0
160 9 2294560 1323433 1309092 1689760 14341 147 128 5 0.762 89234 21159 1954 38511 114244 0 1 0 0
192 10 731520 5349091 5345281 11422492 3810 114 64 3 0.522 421805 88953 51781 71914 614299 0 2 0 0
224 11 4910528 100455 78533 102126 21922 178 128 7 0.962 17484 11997 184 17822 29769 0 1 0 0
256 12 532480 4355 2275 9741 2080 138 16 1 0.942 1567 1491 150 1709 3334 0 0 0 0
320 13 1396480 237483 233119 246338 4364 118 64 5 0.577 40685 9644 320 15525 56803 0 0 0 0
384 14 1465728 3983738 3979921 4947491 3817 393 32 3 0.303 343354 129444 77859 103783 628615 0 0 0 0
448 15 1290688 44620 41739 46691 2881 52 64 7 0.865 17249 6413 68 4018 31177 0 1 0 0
512 16 462848 13132 12228 18149 904 123 8 1 0.918 2557 2559 758 5003 6680 0 1 0 0
640 17 986240 18852 17311 120663 1541 56 32 5 0.859 3579 2811 212 3277 7565 0 0 0 0
768 18 919296 64137 62940 72730 1197 79 16 3 0.946 4707 4744 102 5863 118244 0 0 0 0
896 19 544768 7265 6657 7397 608 21 32 7 0.904 125 180 27 1039 12408 0 0 0 0
1024 20 463872 16008 15555 30525 453 146 4 1 0.775 7568 6457 291 12986 14801 0 0 0 0
1280 21 794880 66259 65638 85300 621 57 16 5 0.680 23326 9109 1169 14047 34993 0 0 0 0
1536 22 489984 7745 7426 5767 319 45 8 3 0.886 3109 3811 212 2799 7389 0 0 0 0
1792 23 336896 4086 3898 4246 188 13 16 7 0.903 2481 3074 29 853 5690 0 0 0 0
2048 24 342016 20391 20224 24607 167 90 2 1 0.927 9681 6317 6406 9277 28971 0 0 0 0
2560 25 371200 23065 22920 31953 145 25 8 5 0.725 9960 8095 662 8805 19444 0 0 0 0
3072 26 384000 4254 4129 2924 125 36 4 3 0.868 1926 2441 529 2256 5479 0 0 0 0
3584 27 189952 3486 3433 3935 53 8 8 7 0.828 2470 2975 76 71 5679 0 0 0 0
4096 28 245760 7238 7178 25144 60 60 1 1 1 4028 3345 7238 0 21890 0 0 0 0
5120 29 225280 1718 1674 42085 44 14 4 5 0.785 1329 1453 98 1246 3054 0 1 0 0
6144 30 172032 2957 2929 7795 28 16 2 3 0.875 2584 2724 704 1415 6790 0 0 0 0
7168 31 35840 1960 1955 1506 5 2 4 7 0.625 1223 1679 320 752 3630 0 0 0 0
8192 32 475136 2873 2815 4116 58 58 1 2 1 2512 2640 2873 0 10938 0 0 0 0
10240 33 163840 25552 25536 24500 16 11 2 5 0.727 12386 5363 11011 4534 39850 0 0 0 0
12288 34 36864 17004 17001 13664 3 3 1 3 1 5602 6158 17004 0 45855 0 0 0 0
14336 35 57344 2984 2980 2181 4 3 2 7 0.666 1610 2114 1008 1307 5827 0 0 0 0
large: size ind allocated nmalloc ndalloc nrequests curlextents
16384 36 19300352 208784 207606 219052 1178
20480 37 20480 4949 4948 5133 1
24576 38 98304 5023 5019 5182 4
28672 39 28672 222 221 222 1
32768 40 131072 166 162 167 4
40960 41 40960 402 401 402 1
49152 42 49152 376 375 376 1
57344 43 0 236 236 236 0
65536 44 0 47738 47738 47738 0
81920 45 245760 2405 2402 2405 3
98304 46 0 2299 2299 2299 0
114688 47 0 543 543 543 0
131072 48 1441792 10448 10437 10448 11
163840 49 0 2878 2878 2878 0
196608 50 196608 2797 2796 2797 1
229376 51 0 1649 1649 1649 0
262144 52 0 891 891 891 0
327680 53 0 1884 1884 1884 0
393216 54 0 4791 4791 4791 0
458752 55 0 1228 1228 1228 0
524288 56 524288 1289 1288 1289 1
655360 57 0 2487 2487 2487 0
786432 58 786432 4971 4970 4971 1
917504 59 0 2595 2595 2595 0
1048576 60 36700160 2512 2477 2512 35
1310720 61 0 4715 4715 4715 0
1572864 62 1572864 5845 5844 5845 1
1835008 63 0 4232 4232 4232 0
2097152 64 0 4413 4413 4413 0
2621440 65 0 8320 8320 8320 0
3145728 66 0 8172 8172 8172 0
3670016 67 0 2825 2825 2825 0
---
6291456 70 0 1250 1250 1250 0
7340032 71 0 1250 1250 1250 0
---
--- End jemalloc statistics ---
Nothing spectactular about that. The 16 KiB blocks are as previously mentioned Ruby pages, used by its internal GC-managed allocator. I decided to look again into profiling on the Ruby side, which was pretty much where I started originally.
Getting rid of bson_ext
I was thinking about profiling the Ruby side of the app, with ruby-prof. Asked again my new-found friends in #ruby if they had some experience with memory leak debugging; they started asking is this really a leak? (good question!). We talked about it, but I didn't get any immediate ideas. I talked to a colleague, and I decided to try a new track: reverting some of the recent changes in Gemfile.lock. A problem I had here was that I didn't really have any "before" figures to talk about, but these things were known:
- The application used to work well, with no apparent sign of out-of-memory on the server.
- The application was moved from JRuby to MRI one month ago.
- At that point or sometime shortly after it, we started seeing these issues.
I did not want to revert it back to JRuby, it at all possible; it doesn't have any Java dependencies and should theoretically be a well-behaved Ruby citizen.
I decided to test one thing: getting rid of bson_ext. It was one of the things I added a few weeks ago, which should improve performance. Could it be the source of the leak? I removed it and restarted the service. Didn't seem to make that big a difference unfortunately...
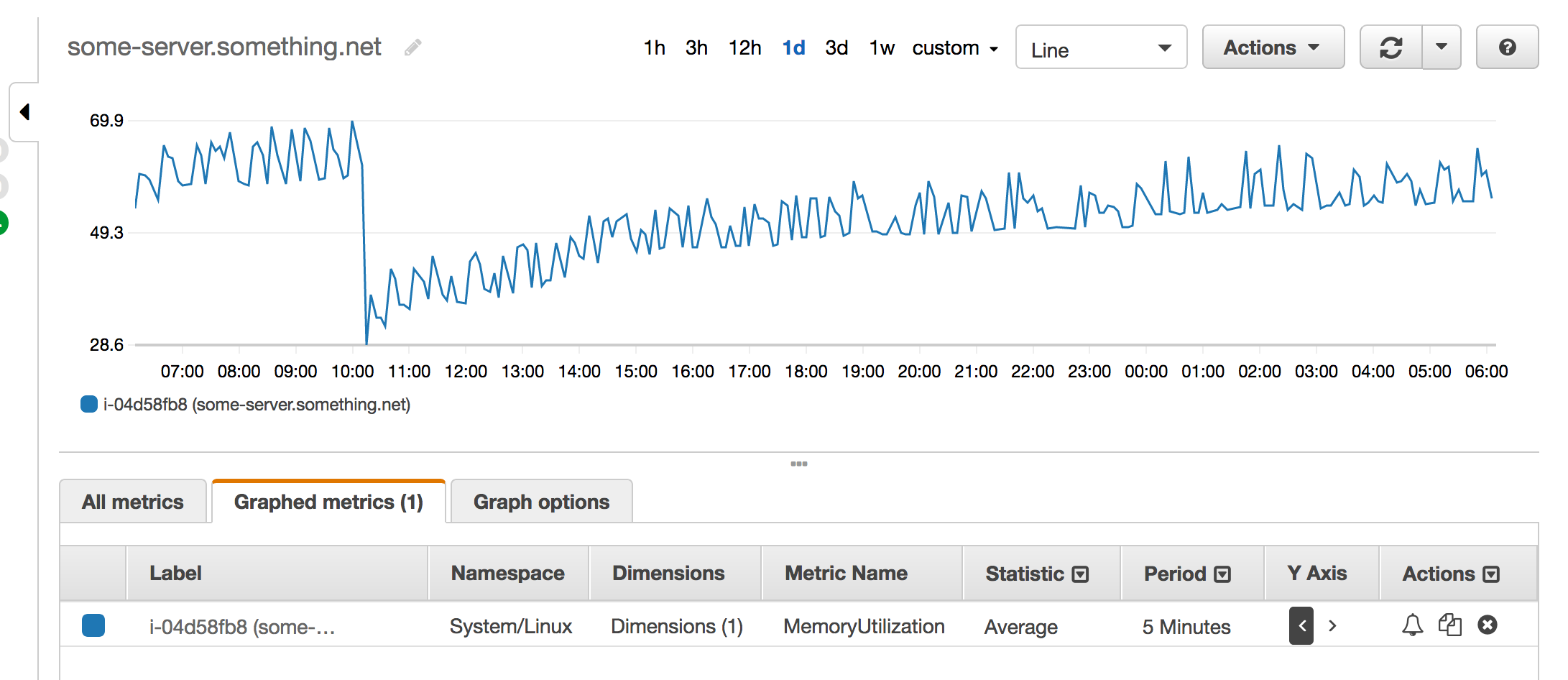
It wasn't entirely clear, but it seemed to still slowly but steadily increase. (At this point, I pretty much felt like throwing the machine out the window; it wasn't really fun anymore. But I am a pretty stubborn person, so I did not want to give up just yet; I could just de-emphasize the debugging for a while, and resume it tomorrow or next week or something.)
The process was now using about 1 GiB of RSS memory. Here are the GC stats:
{
"count": 1745,
"heap_allocated_pages": 1733,
"heap_sorted_length": 2244,
"heap_allocatable_pages": 0,
"heap_available_slots": 706368,
"heap_live_slots": 618531,
"heap_free_slots": 87837,
"heap_final_slots": 0,
"heap_marked_slots": 254749,
"heap_eden_pages": 1733,
"heap_tomb_pages": 0,
"total_allocated_pages": 3097,
"total_freed_pages": 1364,
"total_allocated_objects": 224477545,
"total_freed_objects": 223859014,
"malloc_increase_bytes": 7648184,
"malloc_increase_bytes_limit": 33554432,
"minor_gc_count": 1590,
"major_gc_count": 155,
"remembered_wb_unprotected_objects": 1376,
"remembered_wb_unprotected_objects_limit": 2596,
"old_objects": 229624,
"old_objects_limit": 432048,
"oldmalloc_increase_bytes": 8502640,
"oldmalloc_increase_bytes_limit": 87891137
}
One question that was posed in #ruby was "does it actually run the major GCs?". The data above shows: yes, the major GC runs have been performed 155 times (10 times less than the minor GCs, at 1590.)
Continuing the search on the Ruby side of the fence
I was hoping to be able to pause the debugging for a while (because of lack of motivation, and the problem being quite non-critical in terms of urgency - other more important things to focus on), but after just a few hours I got an email from the CloudWatch monitoring again, saying that the machine was up to 70% memory usage again... The GC stats now looked like this:
{
"count": 2506,
"heap_allocated_pages": 1665,
"heap_sorted_length": 3456,
"heap_allocatable_pages": 0,
"heap_available_slots": 678642,
"heap_live_slots": 624120,
"heap_free_slots": 54522,
"heap_final_slots": 0,
"heap_marked_slots": 448772,
"heap_eden_pages": 1665,
"heap_tomb_pages": 0,
"total_allocated_pages": 6420,
"total_freed_pages": 4755,
"total_allocated_objects": 317085366,
"total_freed_objects": 316461246,
"malloc_increase_bytes": 755040,
"malloc_increase_bytes_limit": 33554432,
"minor_gc_count": 2288,
"major_gc_count": 218,
"remembered_wb_unprotected_objects": 1365,
"remembered_wb_unprotected_objects_limit": 2596,
"old_objects": 429950,
"old_objects_limit": 446732,
"oldmalloc_increase_bytes": 28834312,
"oldmalloc_increase_bytes_limit": 94102940
}
As can be seen, old_objects was up with 200 000 objects in just a few hours. Something seemed to be leaking on the Ruby side, indeed. But hey, didn't my earlier graph indicate the contrary, that the number of old_objects was more or less constant? It could be that my isolated tests hadn't managed to fully reproduce the problem...
I had previously tried with VCR/Webmock, but it seemed to leak so much memory in itself that it wasn't really of any help in this case. However, I had an idea: what if I'd proxy the Trello responses via an auto-replying web proxy instead? That way, I can avoid hammering the Trello API with requests, but still get a test scenario which is more similar to the "real world" production use case. Said and done, I configured my application server like this:
$ http_proxy='http://10.211.55.3:8888' bundle exec uxfactory
...and tweaked my app to disable SSL certificate verification (do not do this unless you understand the consequences very well):
OpenSSL::SSL::VERIFY_PEER = OpenSSL::SSL::VERIFY_NONE
I then configured Fiddler to auto-respond to these URLs:
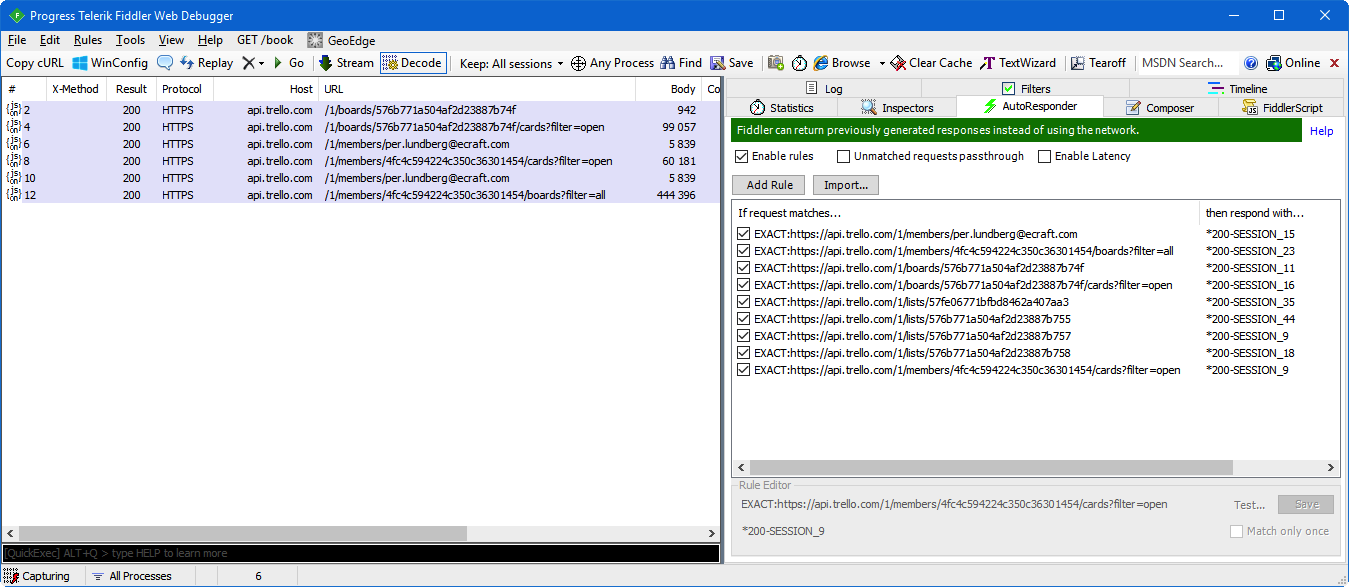
That way, I could run these specific API endpoints without using up all our Trello API quota. Great! Once again, Erik Lawrence's tool turned out to be an absolutely invaluable thing.
(Oh, and by the way, don't spend time trying to impersonate me; these Trello URLs require OAuth authentication anyway. ![]() )
)
Now, let's hammer the server with these specific URLs; we already know (or well, believe) that the other MongoDB-only URLs do not leak memory on the Ruby side.
$ siege -v -c5 -f urls.txt
It didn't work very well; it was slow and didn't really run very many requests per second. It was up to 100 megabytes or so after maybe a few hundred hits, but the sample was too small to be able to prove anything. I felt like it should continue to run for a while, but I didn't want this to sit and eat up my valuable CPU resources etc, so I was considering (and started) setting up on another machine. It would be a bit of work though, especially since I normally run Fiddler on Windows (can probably work in Mono but still, it and a lof of other things have to be set up to get the app running.)
It didn't seem like an optimal path forward.
I decided to once more restart the production service, since the machine was already at 70% memory usage. Then I enabled ObjectSpace tracing again. I waited until it got up to 60-70% next time before continuing.
The RSS was now 1267 megabytes. old_objects was up to 430356. I generated new heap dump, and looked at it with heapy, but it seemed fishy so I filed an issue about it. It was Friday night and I didn't really have time to dig deeper into it, so I just restarted it once more... (Actually, I rebooted the whole server since it was pending some Ubuntu updates as well.) Hopefully that would be enough to keep it quiet during the weekend, and then I'll pick up the digging on Monday (again...)
Trying with Ruby 2.5.0-dev
As already mentioned, I was quite tired of the whole thing by now, but I had some ideas left:
- Move over to debugging this on the real production server. Clearly not ideal, but we still didn't have any really good repro case of this in the isolated tests I had been making. The production environment was the best reproduction of the problem we had at the moment, so it was time to try and solve this in production. I had two ideas:
- Try with Ruby 2.5.0-dev, i.e. latest code from git. Would it reproduce the problem or would it be "gone"?
- If that fails, enable the
jemallocdebugging in production and let it create the exit profiling (i.e. when the process exits) and see what we can get out of it.
The production server is running on Docker and traffic is reverse-proxied via an nginx server, so diverting the traffic for this particular app to another Ruby runtime version would be quite simple. I just have to start a new container based on the existing one, exposing a different port, and in that container compile the Ruby runtime of choice (in this case, the container has gcc and similar tools installed, which is bad from a security standpoint but for cases like this, it happens to be convenient...).
So I did just that:
$ sudo docker commit 29ec961c7ddf temp-image
$ sudo docker run -p 12345 temp-image
...and compiled Ruby 2.5.0-dev, ran bundle install etc. so I could boot the service. (Technically, it was a bit more complex than this because of how the container was structured, but allow me to simplify things a bit to make the story flow better.)
I set the nginx config to use the new host port, and detached the screen I was ad-hoc-running the service in temporarily. Now all I had to do was wait, again...
Next morning, the RSS size was around 690 MiB and heap_allocated_pages was 1919, with old_objects 574988. I waited a bit more to see if it would continue growing.
The next day, right when I woke up, I had an idea: how about googling for "ruby 2.4.1 memory leak"? Said and done, I did just that and found rest-client/rest-client#611, which pointed at Bug #13772: Memory leak recycling stacks for threads in 2.4.1. Interesting!
This was quite well-aligned with what I was seeing in the memory usage graphs for the server now, when running with 2.5.0-dev (where the MRI bug is fixed), but I still felt that the data was a bit inconclusive so I decided to give it at least one more full day before any further action (which would be downgrading to 2.3.4 in this case). I ended up running it for a few days. This is what the graph looked like:
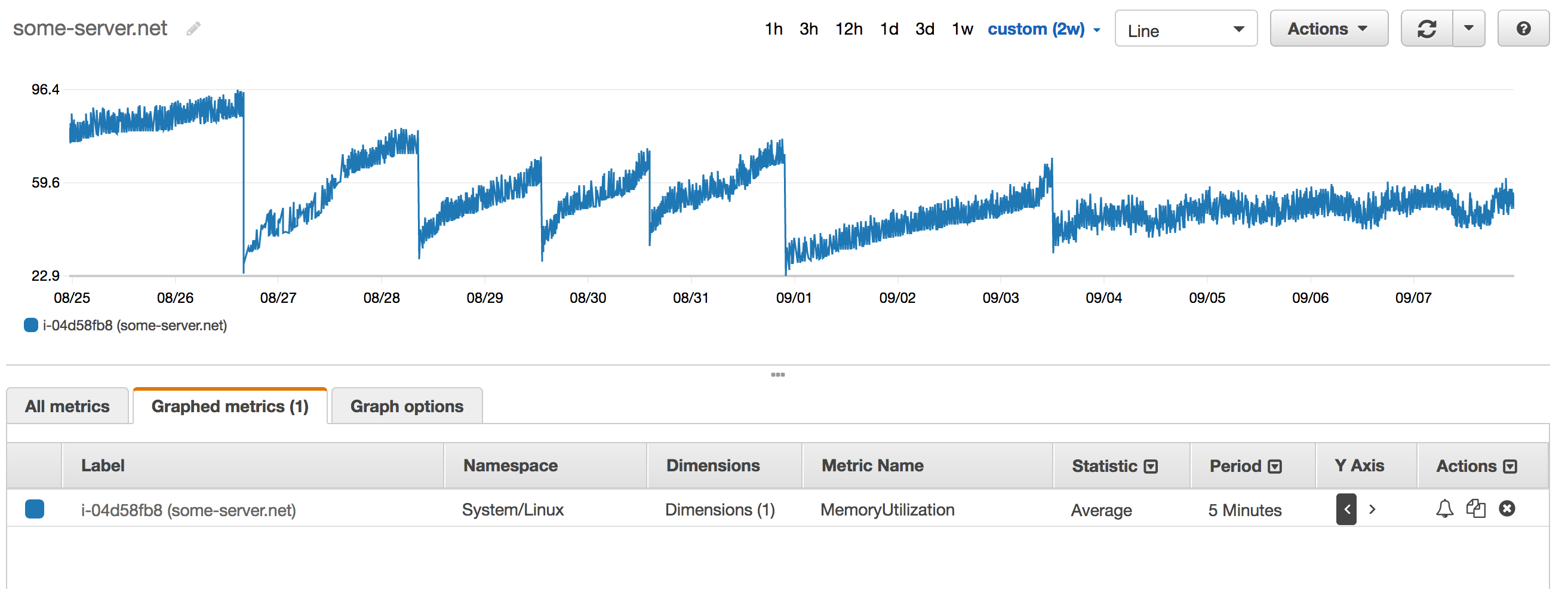
The six left-most parts of the graph are before I bumped the Ruby version to 2.5.0-dev. Do you see how it differs from the right-most part? Instead of going steadily upward over time, the memory usage tends to be more or less constant. It is reasonable to assume that the root cause of the leak has been found.
If you read all of this, you remember me mentioning bson_ext as a potential source of leakage. I don't think it is, not until proven otherwise, so I will probably put it back into my Gemfile shortly after this. CloudWatch will email me if it turns out to be an incorrect assumption. ![]()
I ended up downgrading to Ruby 2.3.4 for now, but I also asked the Ruby maintainers to release a 2.4.2 version if possible. Actually, when graphing the memory usage over time, I am not 100% sure that all leaks are gone yet (memory usage still seems to increase a bit over time), but at least this very real bug has been fixed, which is good... Time will tell, and the automated monitoring emails I get will show whether we have something more that remains to be investigated or not.
Update: Ruby 2.4.2 was released shortly after this, which fixes the acknowledged leak. Thanks for this, Ruby core team!
Conclusions
-
Never rule out anything: compiler bugs, runtime bugs, etc. I have seen crazy things sometimes, for example when different versions of
gcccaused input parameters to inline assembly code to be placed as stack parameters instead of in registers (as used to be the case with a previous version, using the same source code). Since the inline assembly code was itself pushing stuff on the stack before using the parameters provided, the stack pointer would have a different value than the compiler assumed => broken code.The core point here is: when debugging, don't make assumptions. And if you do, assume that your assumptions are wrong. Be open for the unexpected; it might be the reason for the problem you're investigating.
Be perseverent and you will eventually find the root cause, if you don't give up. I was close to giving up a couple of times in this debugging. It was fun in the beginning, but eventually got pretty boring and dull. Like many tasks in life. But, when it starts to feel like this, don't give in. Keep pressing on; you will eventually see that light at the other end of the tunnel that you're so desperately longing for.
I was actually on the right track when genering the jemalloc graph early on. Let's look at it one more time:
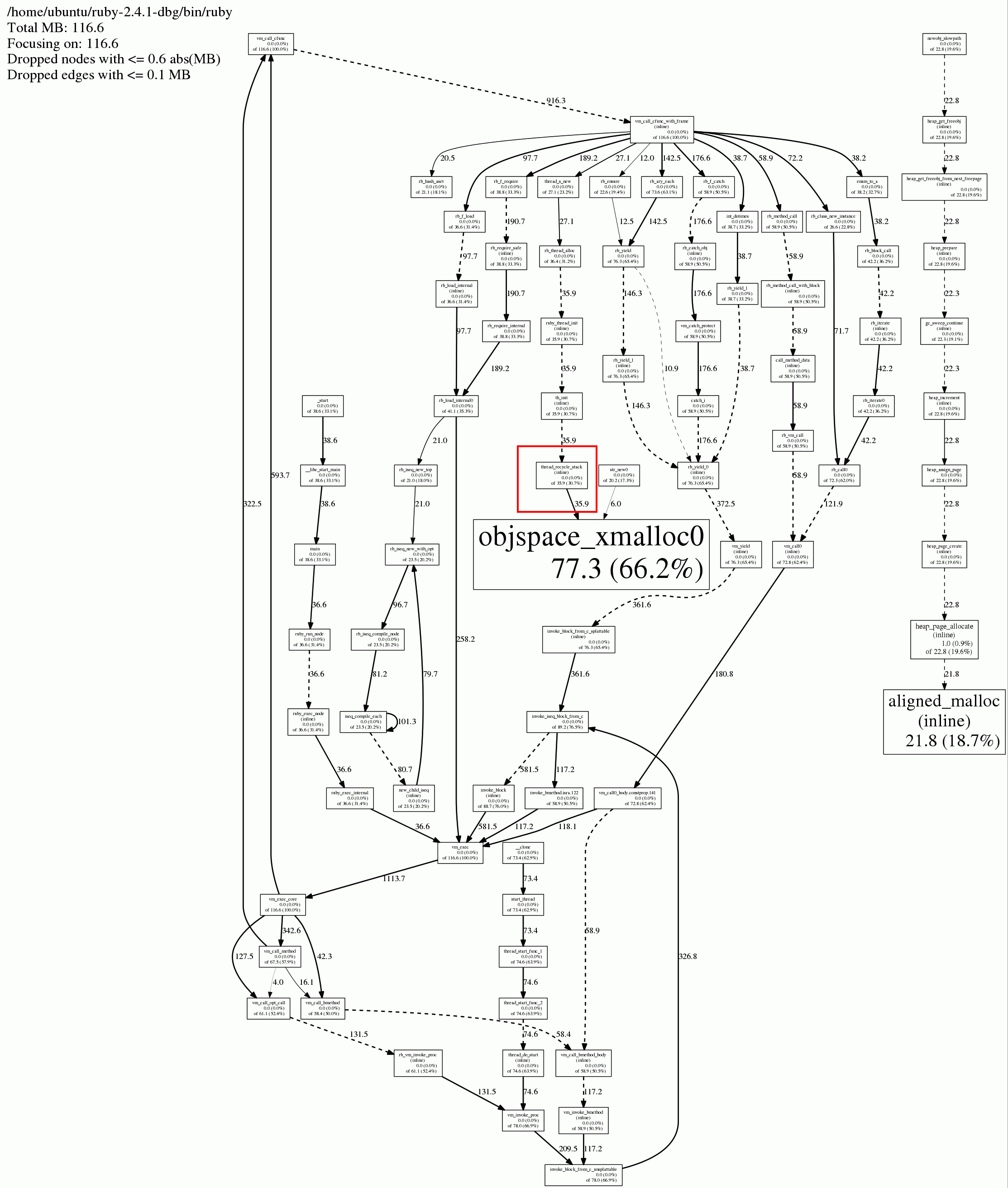
I highlighted (in red) the exact same method that is mentioned in Bug #13772: Memory leak recycling stacks for threads in 2.4.1. When I generated that graph, I was looking for something else, but isn't it interesting how "obvious" it is now when we know for a fact that this was indeed the source of the leak? ![]() The next time I see something like this, it will be easier to interpret the graphs I think.
The next time I see something like this, it will be easier to interpret the graphs I think.
Anyway, I hope we have all learned a bit about this subject now; I have definitely learned new things myself. The tools that Sam Saffron mention in bug #13722 (heaptrack and massif-visualizer) are also probably pretty useful when dealing with these kind of more "weird" memory leaks. And jemalloc is a great starting tool for getting into debugging memory profiling in C-based codebases. Peace!